首先声明,汉语大词典光盘版3.0数据的提取现在没什么实际意义,写这篇文章只是出于兴趣以及存个档。
许多年前(2016年),我在论坛上发过一个汉语大词典光盘版3.0的提取工具:汉语大词典光盘版3.0及提取工具 – 词库制作交流区 – Dictionary-Making – 掌上百科 – PDAWIKI – Powered by Discuz!。
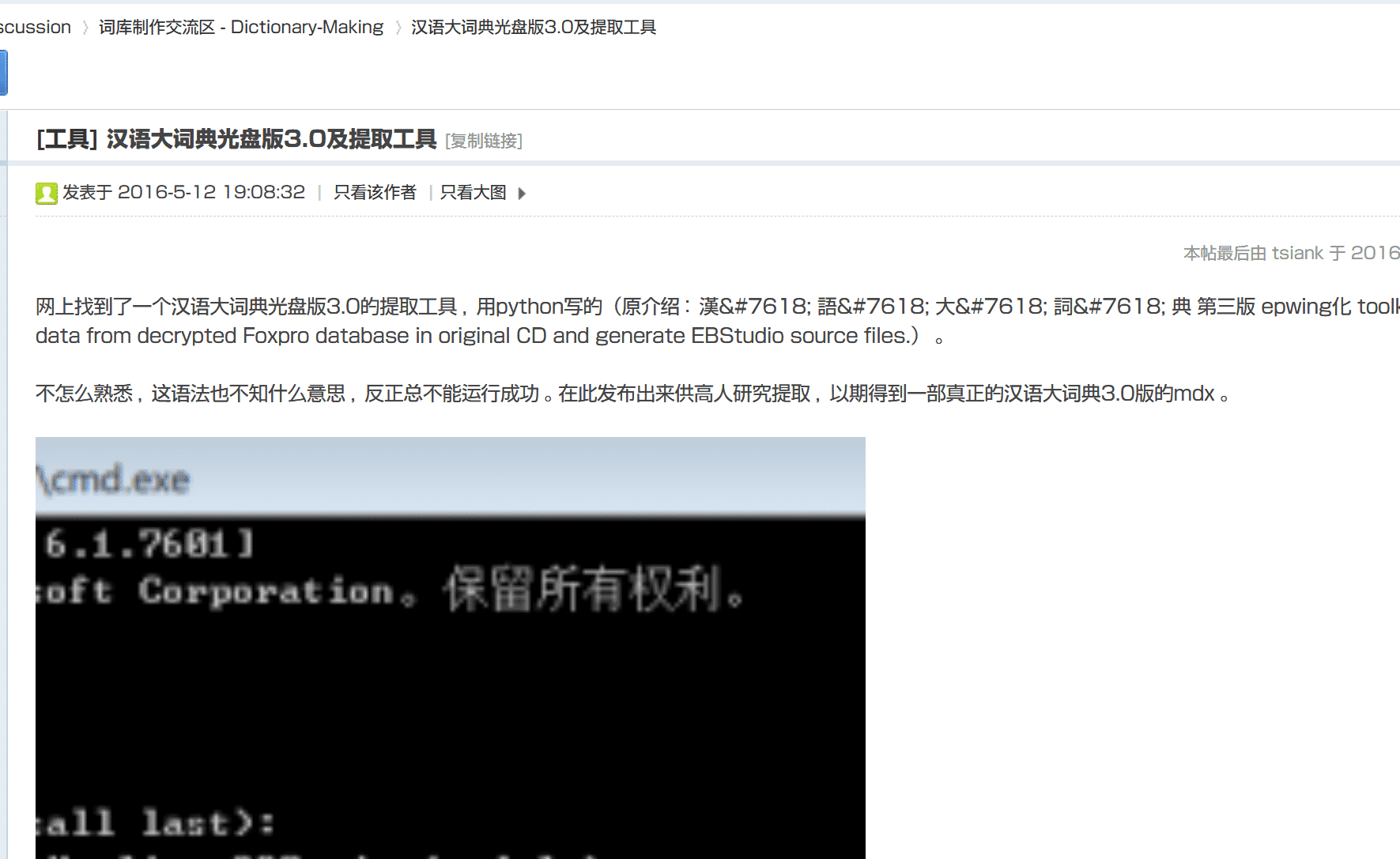
这个工具是我在网上偶然搜到的,下载需要10元钱,想着还能出得起,于是就付款下载了。现在搜了下,这个网站以及这个工具都还在。可以看到,这个工具2010年就已经写出来了,上传是在2012年,而我找到它已经是上传四年后了。
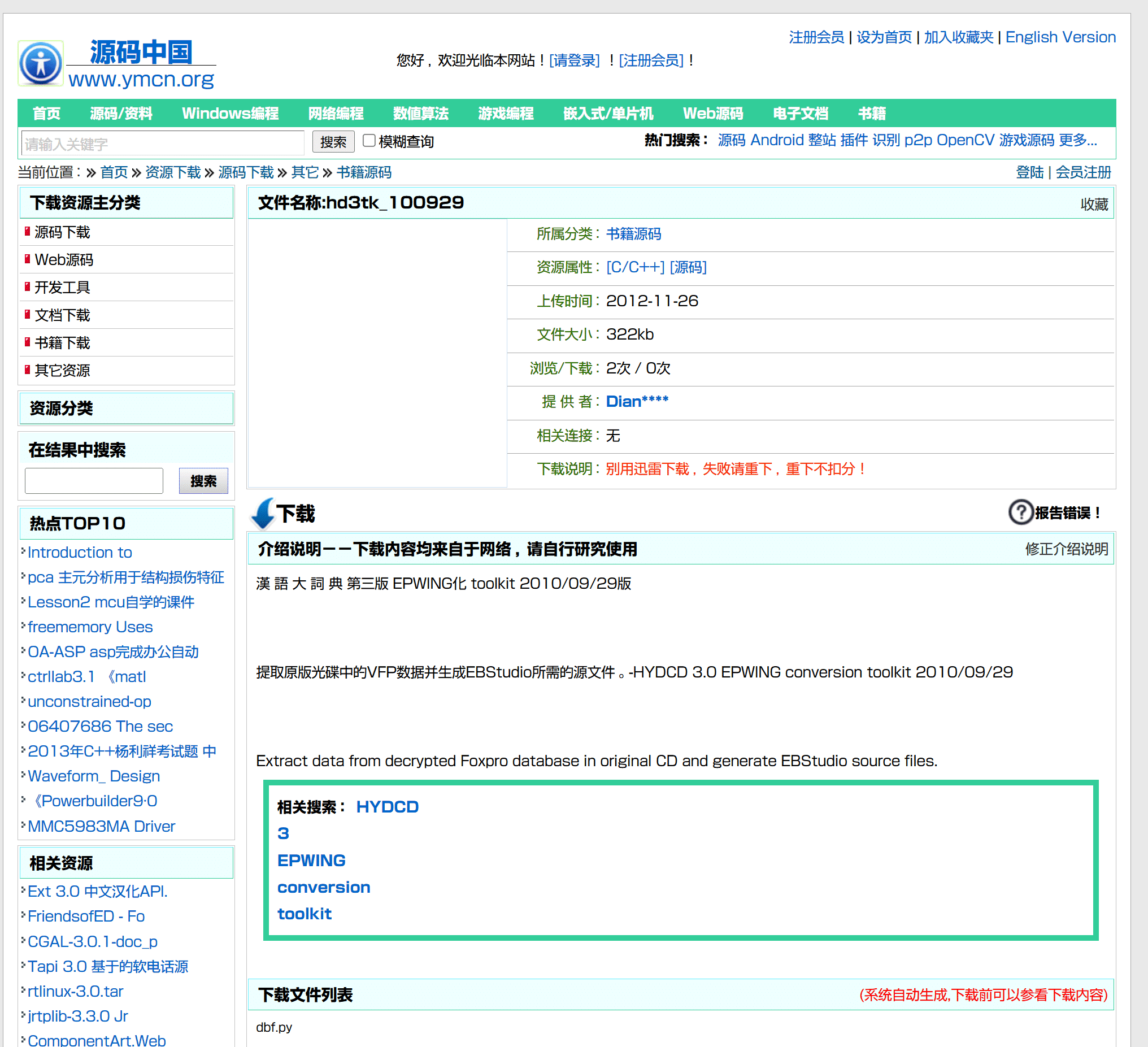
之所以下载这个工具,是因为当时对已发布的汉语大词典文本版的mdx都不满意,想要从源头重新制作(一开始并没想到光盘版3.0相对于2.0是种倒退)。这个工具是用python写的,当时并不懂这些代码,于是就发到论坛上,期待有高手出手解决,同时自己使用笨办法去先行提取。
没想到很快真有高手(gnoweb网友)出现,不但制作并分享了他提取出的大词典文本,而且公布了这个工具的编译方法(涉及到C代码的编译)。
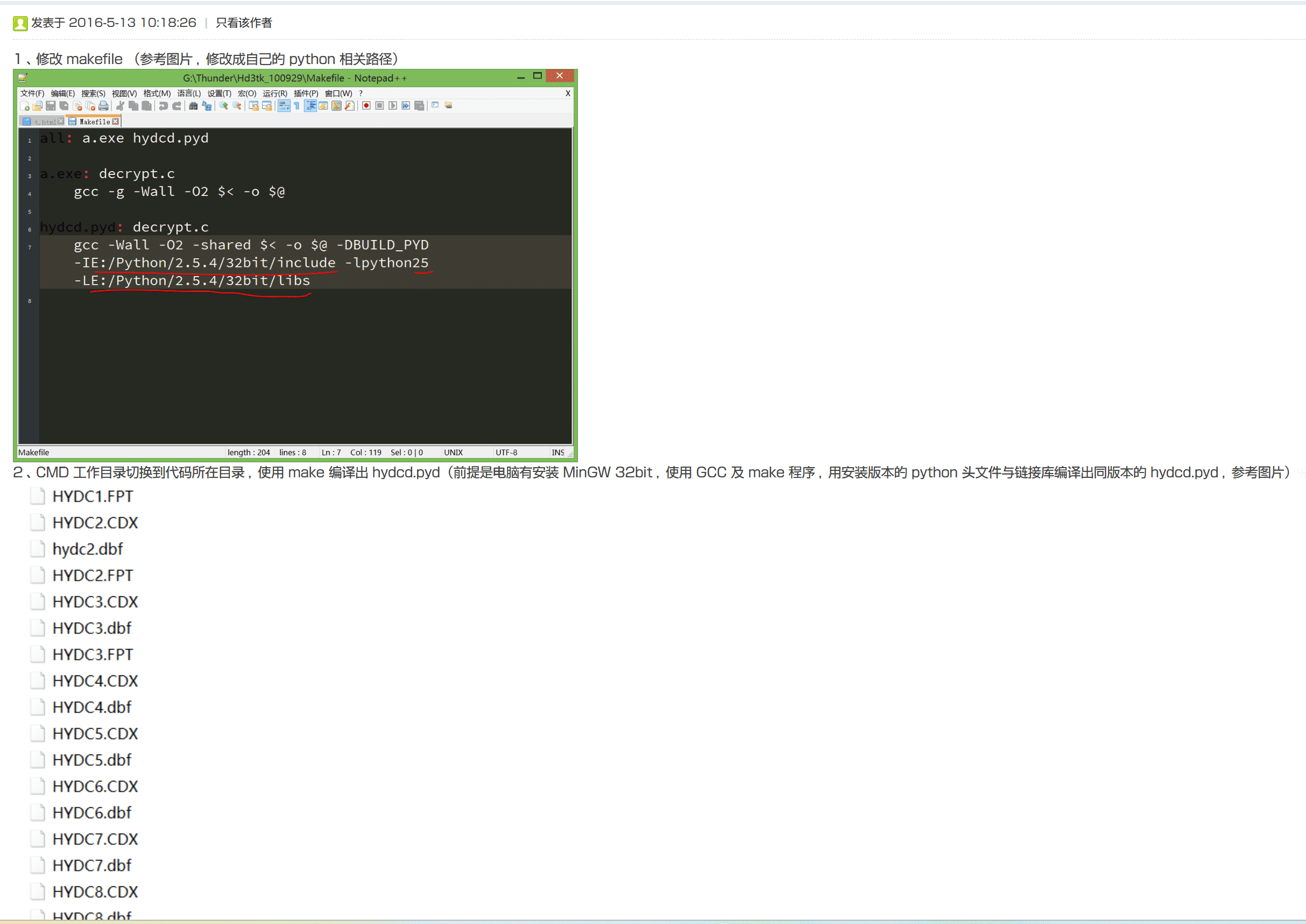

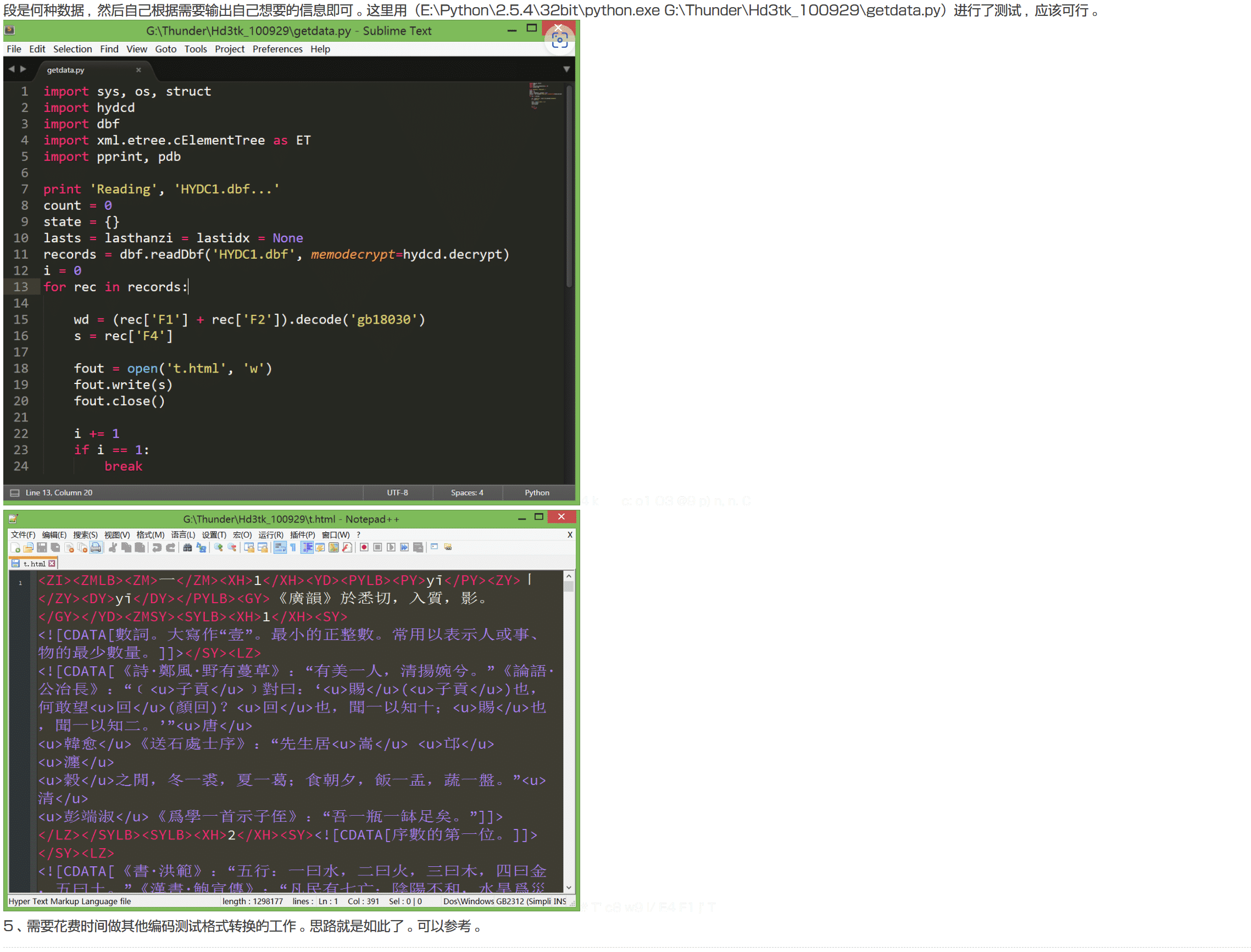
我按步骤做了下,没编译成功,不过既然得到了源文本,也就无须再操作下去了,遂放弃。
如今对python已略知一二,对C编译也可照猫画虎,近段时间忽然心血来潮,想要亲自再编译及提取试试看。于是找到当年帖子,按照操作步骤,终于成功编译,也成功提取。不过第四步原文说“这个步骤会运行出错(主要是涉及编码转换的)”,因此他又写了自己的代码来处理这种转换。我在运行时并没有发现错误,只是出了几个警告,似乎是几个词头链接问题。
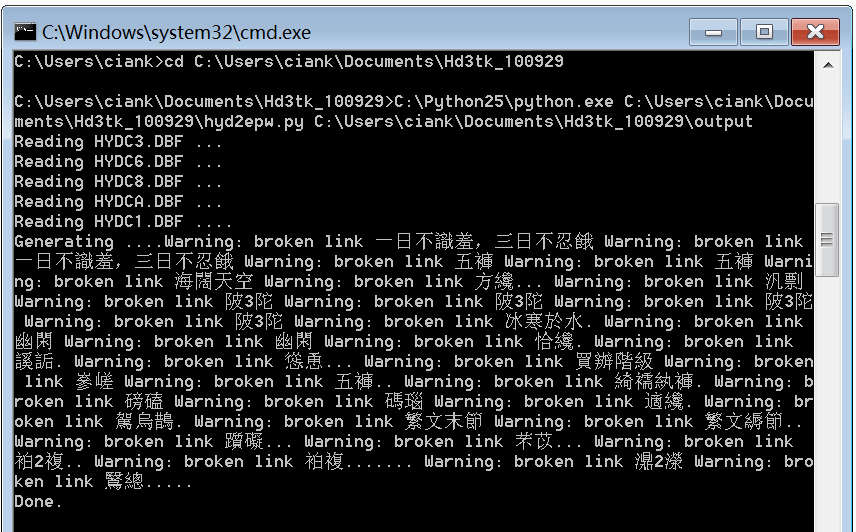
output文件夹里也正常生成了提取后的文件,打开文件,编码显示是日语(Shift-JIS),把里面的html引用转换为unicode并保存为UTF8格式即为正常的文本。
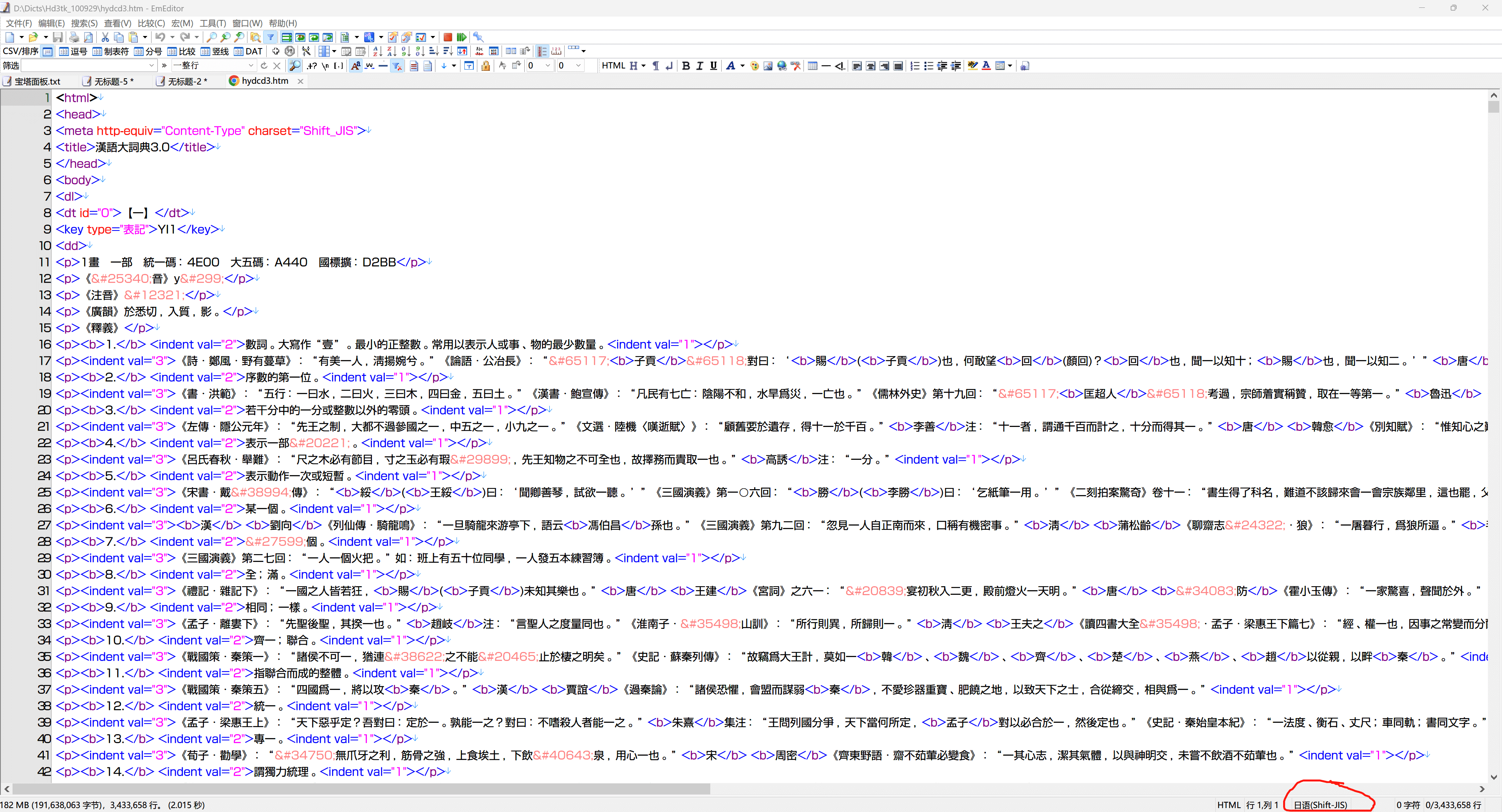
在重新制作3.0数据的过程中,发现了源数据有许多问题,原帖子下面也有许多讨论,最终认识到光盘版3.0相对于2.0是种倒退,于是把重心转向了重新制作大词典2.0。当时就用过这个工具试着提取2.0数据,实际证明行不通,两个光盘的数据结构和加密都不一样,运行直接报错,于是只得使用笨办法处理(有空再写)。
有整理《大词典》单字字头吗
文林上有整理